Основы R
Это мой первый опыт в создании и редактировании сайта. В ближайшее время я буду вносить изменения в формат и в содержание постов, но пока так.

В курсе мы будем использовать язык R. Он относительно простой и удобный, а главное - бесплатный! Если вы его ещё не установили - самое время это сделать по ссылке! После установки R необходимо поставить экосистему RStudio - она очень удобная и сделает знакомство с R наиболее безболезненным. Когда вы впервые запустите RStudio, создайте рабочее пространство, кликните на верхней панели Session -> Set Working Directory -> Choose Directory. Теперь ваш код и файлы с данными для этого курса никуда не потеряются. Самое время настроить ваше рабочее пространство в R и получить первый опыт работы. Для этого советую короткое видео.
Введение
Обычно в начале требуется какое-то вступительное слово, но у меня его нет. Поэтому начнём мы с анекдота от искусственного интеллекта:
Однажды на конференции по математической статистике один из участников гордо заявил, что его метод имеет “p-value” на уровне значимости меньше 0,0001. Внезапно из зала послышался голос другого участника, который спросил: “А что такое p-value?” Первый участник перестал уверенно улыбаться и начал объяснять сущность этого статистического понятия. Его описание было настолько запутанным и непонятным, что зал начал смеяться. Второй участник поднял руку и сказал: “Спасибо за объяснение, теперь я понимаю, что p-value - это как раз то, чего я не хочу получить в своих экспериментах!”
Анекдот про эконометрику от Chat GPT.
Сегодня познакомимся с:
Tidyverse- пожалуй, самой удобной на сегодня библиотекой для манипуляции данными;Stats- уже включённой в R библиотекой для статистического моделирования.
Давайте загрузим библиотеку Tidyverse:
library(tidyverse)
Векторы и таблицы
Чтобы задать вектор в R мы используем функцию c(). Например, у нас есть три друга: Боря, Настя и Алина. Зададим вектор друзей:
friends <- c('Боря', 'Настя', 'Алина')
Давайте посмотрим на этот объект внимательно:
str(friends)
## chr [1:3] "Боря" "Настя" "Алина"
Сообщение выше значит, что friends - это вектор с 3-мя значениями в текстовом формате.
Допустим, мы хотим выбрать одного друга из нашего вектора друзей. В R, как и во многих других языках, это делается через индекс в скобочках []. Допустим, мы хотим выбрать второй элемент:
friends[2]
## [1] "Настя"
Также мы можем создать другие векторы:
age <- c(22, 25, 24)
fav_movie <- c('Убить Билла', 'Робокоп', 'Броненосец Потёмкин')
dota_hours_played <- c(0, 2, 15000)
Из этих векторов мы можем собрать табличку - data.frame. Мы будем очень много работать с ними в курсе.
data.frame(Имя = friends,
Возраст = age,
`Любимый фильм` = fav_movie, # я использую ``, чтобы задать название переменной с пробелом. Обчыно мы пишем _ вместо пробела, но в образовательных целях я сейчас написал так.
`Наиграно часов в Доту` = dota_hours_played,
check.names = F # опция, которая не исправляет имена
)
## Имя Возраст Любимый фильм Наиграно часов в Доту
## 1 Боря 22 Убить Билла 0
## 2 Настя 25 Робокоп 2
## 3 Алина 24 Броненосец Потёмкин 15000
На данный момент эта табличка не сохранена у нас в памяти, потому что мы не связали с ней никакой объект. Добавим в неё логическую переменную Геймер и сохраним в память под именем data:
data <- data.frame(Имя = friends,
Возраст = age,
`Любимый фильм` = fav_movie,
`Наиграно часов в Доту` = dota_hours_played,
check.names = F # опция, которая не исправляет имена
) %>%
mutate(Геймер = ifelse(`Наиграно часов в Доту` >= 1000, T, F)
)
data
## Имя Возраст Любимый фильм Наиграно часов в Доту Геймер
## 1 Боря 22 Убить Билла 0 FALSE
## 2 Настя 25 Робокоп 2 FALSE
## 3 Алина 24 Броненосец Потёмкин 15000 TRUE

Сейчас мы использовали две новые функции:
mutate()- создаёт или изменяет уже созданные переменные. Подробнее - в документации:?mutate()ifelse()краткое написание логического утверждения. В нашем случае мы задали условие, если переменнаяНаиграно часов в Доту >= 1000, то наш друг - геймер (и в последний раз мы видели его несколько лет назад), второй аргумент,T- значитTrue, условие выполнено. Иначе -F-False, наш друг - не геймер.
мы можем выбрать определённый столбец из нашей таблицы, написав $ после названия таблицы и нажав Tab. R сам предложит вам столбец на выбор. Например:
data$Геймер
## [1] FALSE FALSE TRUE
Обработка данных:
У нас есть данные по различным сборкам ноутбуков и их ценам. Давайте потренируемся обрабатывать данные этом примере. В будущих лекциях мы построим модель ценообразования на рынке ноутбуков (это поможет нам найти самые недооценённые ноутбуки и сформировать свой высокодоходный портфель ноутбуков)!
data <- read.csv('https://raw.githubusercontent.com/ETymch/Econometrics_2023/main/Datasets/laptop_price.csv')
data %>%
arrange(Company) %>% # Упорядочить таблицу по алфавиту, используя название фирмы изготовителя
head()
## laptop_ID Company Product TypeName Inches
## 1 6 Acer Aspire 3 Notebook 15.6
## 2 10 Acer Swift 3 Ultrabook 14.0
## 3 37 Acer Aspire 3 Notebook 15.6
## 4 44 Acer Aspire A515-51G Notebook 15.6
## 5 52 Acer Aspire A515-51G Notebook 15.6
## 6 55 Acer Aspire 3 Notebook 15.6
## ScreenResolution Cpu Ram Memory
## 1 1366x768 AMD A9-Series 9420 3GHz 4GB 500GB HDD
## 2 IPS Panel Full HD 1920x1080 Intel Core i5 8250U 1.6GHz 8GB 256GB SSD
## 3 1366x768 Intel Core i3 7130U 2.7GHz 4GB 1TB HDD
## 4 IPS Panel Full HD 1920x1080 Intel Core i5 8250U 1.6GHz 4GB 256GB SSD
## 5 IPS Panel Full HD 1920x1080 Intel Core i7 8550U 1.8GHz 8GB 256GB SSD
## 6 1366x768 Intel Core i3 7100U 2.4GHz 4GB 1TB HDD
## Gpu OpSys Weight Price_euros
## 1 AMD Radeon R5 Windows 10 2.1kg 400
## 2 Intel UHD Graphics 620 Windows 10 1.6kg 770
## 3 Intel HD Graphics 620 Linux 2.1kg 367
## 4 Intel UHD Graphics 620 Windows 10 2.2kg 682
## 5 Nvidia GeForce MX150 Windows 10 2.2kg 841
## 6 Intel HD Graphics 620 Windows 10 2.4kg 384
Когда мы пишем код в R мы часто используем %>% - трубочки. Всё просто: допустим мы хотим последовательно применить к объекту несколько функций. Помните, в курсе по математике были вложенные функции \(f(g(x))\)? Тогда это значило, что к объекту \(x\) мы сначала применяли функцию \(g\), затем функцию \(f\). При помощи %>% мы можем написать это так: x %>% g() %>% f(). Хороший тон - писать такие функции в столбик - тогда код удобно читать. Если мы захотим последовательно применить много функций (для манипуляции сложным объектом), то код, написанный первым подходом становится нечитаемым. Например: datatable(head(group_by(Data, Company))).
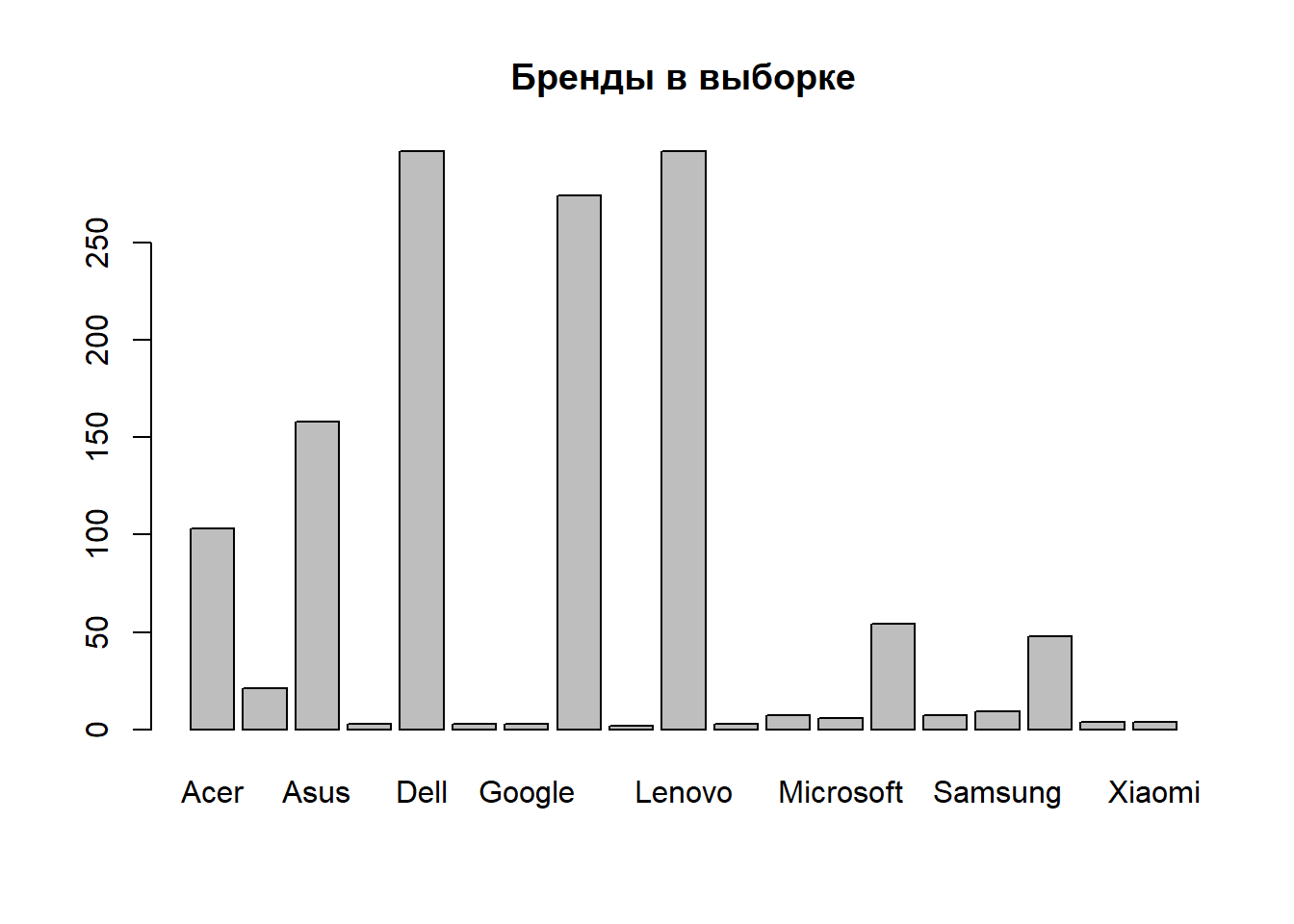
Давайте посмотрим, какие бренды представлены в выборке:
data$Company %>%
as.factor() %>% # меняем тип данных
plot(main = 'Бренды в выборке')
Давайте посмотрим на распределение цен в выборке:
data$Price_euros %>%
hist(main = 'Распределение цен ноутбуков')# Гистограмма
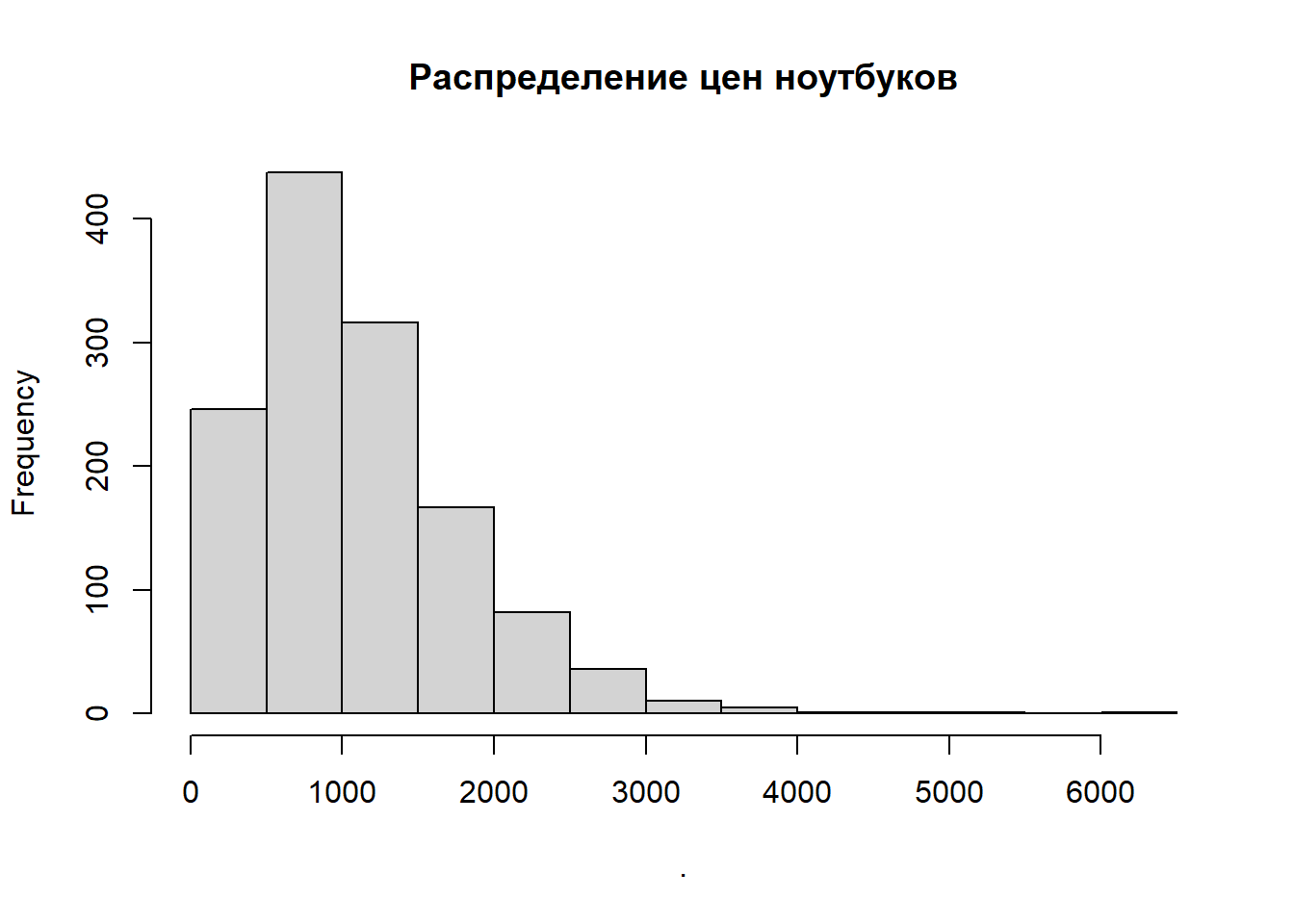
На графике заметно, что есть какие-то супердорогие ноутбуки, которые стоят более 4k евро! Давайте посмотрим на них.
data %>%
filter(Price_euros >= 4000) # Выбрать наблюдения на основании критерия
## laptop_ID Company Product TypeName Inches
## 1 200 Razer Blade Pro Gaming 17.3
## 2 617 Lenovo Thinkpad P51 Notebook 15.6
## 3 758 HP Zbook 17 Workstation 17.3
## 4 839 Razer Blade Pro Gaming 17.3
## ScreenResolution Cpu Ram
## 1 4K Ultra HD / Touchscreen 3840x2160 Intel Core i7 7820HK 2.9GHz 32GB
## 2 IPS Panel 4K Ultra HD 3840x2160 Intel Xeon E3-1535M v6 3.1GHz 32GB
## 3 IPS Panel Full HD 1920x1080 Intel Xeon E3-1535M v5 2.9GHz 16GB
## 4 4K Ultra HD / Touchscreen 3840x2160 Intel Core i7 7820HK 2.9GHz 32GB
## Memory Gpu OpSys Weight Price_euros
## 1 1TB SSD Nvidia GeForce GTX 1080 Windows 10 3.49kg 6099
## 2 1TB SSD Nvidia Quadro M2200M Windows 10 2.5kg 4899
## 3 256GB SSD Nvidia Quadro M2000M Windows 7 3kg 4389
## 4 512GB SSD Nvidia GeForce GTX 1080 Windows 10 3.49kg 5499
Потренируйтесь:
- Какую долю в выборке составляют ноутбуки HP?
- Выберите эти ноутбуки и нарисуйте гистограмму распределения цен.
- Верно ли, что разрешение экрана у ноутбуков ASUS в среднем выше, чем у ноутбуков Dell?
Оптимизация
В вступительном тесте у вас была задача оптимизации. $$\min_x{(3-3x)^2}$$
Иначе говоря, мы хотим найти такой \(x\), чтобы интересующая нас функция \((3-3x)^2\) приняла минимальное значение. Есть несколько способов её решить.
- Из школьного курса мы помним, что
\((3-3x)^2\)- вогнутая парабола (с ветками вверх). Значит она имеет 1 решение, догадаться до которого просто, при\(x = 1\)функция принимает значение 0. - Взяв производную, мы найдём точку, в которой касательная к графику параллельна оси функции.
$$[(3-3x)^2]' = -12(3-3x) = 0$$Следовательно,\(x = 1\). Искомая функция принимает значение 1. - Мы можем быстро запрограммировать этот пример. Помните, в этом курсе использование компьютера поощряется всегда. Напишем функцию:
f <- function(x){
(3 - 3*x)^2
}
Нарисуем её на промежутке [-5;5]:
x = seq(-5, 5, by = 0.01) # вектор от -5 до 5 с шагом 0.01.
plot(x, f(x), col = 'lightblue')
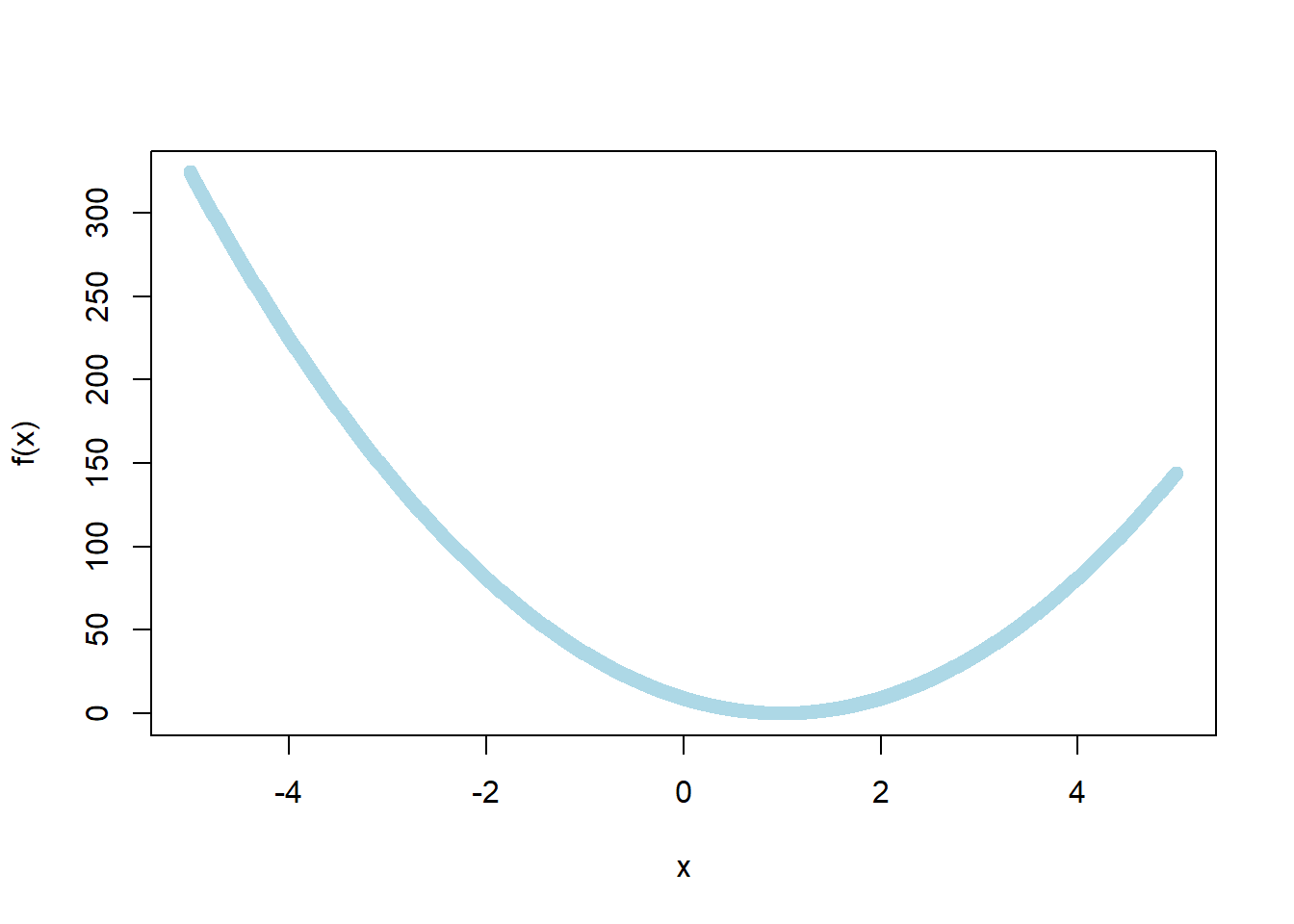 Да, очевидно это вогнутая парабола. Найдём минимум:
Да, очевидно это вогнутая парабола. Найдём минимум:
optimize(f, x)
## $minimum
## [1] 1
##
## $objective
## [1] 0
Функция принимает минимальное значение 0 при \(x = 1\)
Мы решили задачу оптимизации!

Теперь ваш черёд! Решите аналитически и при помощи R, постройте график:
$$\max_x\{3 - 10x - 2x^2\}$$
Интегрирование:
В курсе нам иногда нужно будет вычислить вероятности различных событий - для этого потребуется взять интеграл. Давайте вспомним, как считать интегралы на примере:
$$F(x) = \int_{-\infty}^{0} e^{2x + 1}dx = \frac{1}{2}e^{2x+1}|^0_{-\infty} = \frac{1}{2}e - 0 = \frac{1}{2}e$$
f <- function(x){
return(exp(2*x+1))
}
integrate(f, -Inf, 0)
## 1.359141 with absolute error < 6.8e-07
Если вам нужно взять интеграл аналитически - не нужно вспоминать всю теорию, пользуйтеся языками программирования, например, Mathematica.