Библиотеки
library(tidyverse)
library(hrbrthemes)
library(stargazer)
library(reshape2)
Данные
Сегодня мы построим модель, которая позволит диагностировать сахарный диабет, на основании различных данных о пациенте.
dta <- read_csv('https://raw.githubusercontent.com/ETymch/Econometrics_2023/main/Datasets/framingham.csv')
test <- sample_n(dta, 800) # тестовая выборка. На ней мы будем проверять модели.
train <- setdiff(dta, test) # на этой выборке мы будем оценивать модели
Почему в данном случае МНК - не лучший вариант для оценки параметров?
Наиболее значимым фактором для постановки такого диагноза является уровень глюкозы в крови. Построим график зависимости диагноза от кровня глюкозы:
dta %>%
ggplot(aes(x = glucose, y = diabetes)) +
geom_point() +
geom_smooth(method = 'lm') + # добавим линию, оценённую с помощью МНК
geom_vline(xintercept = 99, color = 'red') + # Верхняя граница нормы
theme_ipsum() +
labs(x = 'Уровень глюкозы в крови, мг./Дл.',
y = 'Сахарный диабет')
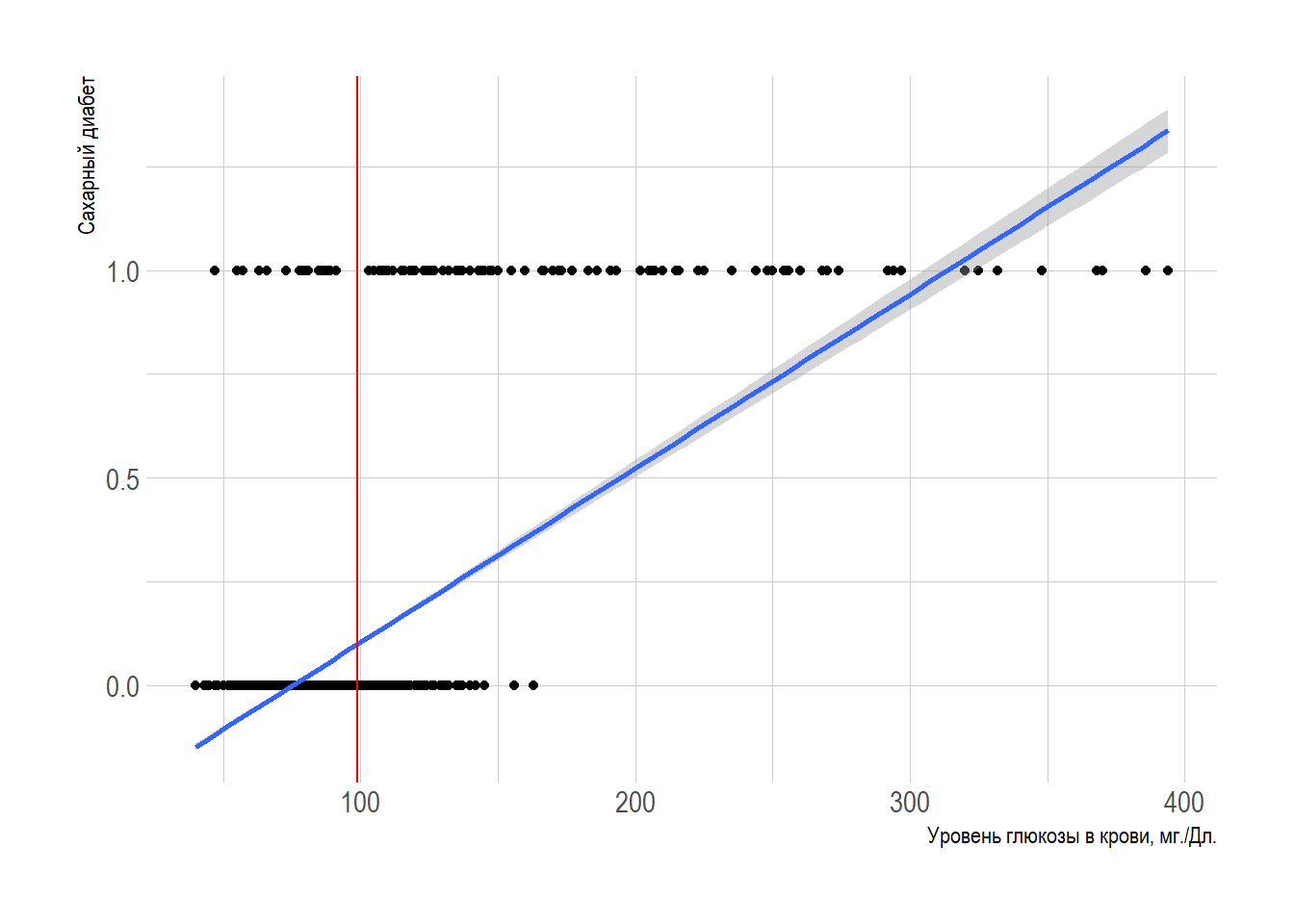
Линия плохо описывает взаимосвязь. Возможно, такая форма лучше?
dta %>%
ggplot(aes(x = glucose, y = diabetes)) +
geom_point() +
geom_smooth(method = "glm",
method.args = list(family = "binomial"),
se = FALSE) +
geom_vline(xintercept = 99, color = 'red') +
theme_ipsum() +
labs(x = 'Уровень глюкозы в крови, мг./Дл.',
y = 'Сахарный диабет')
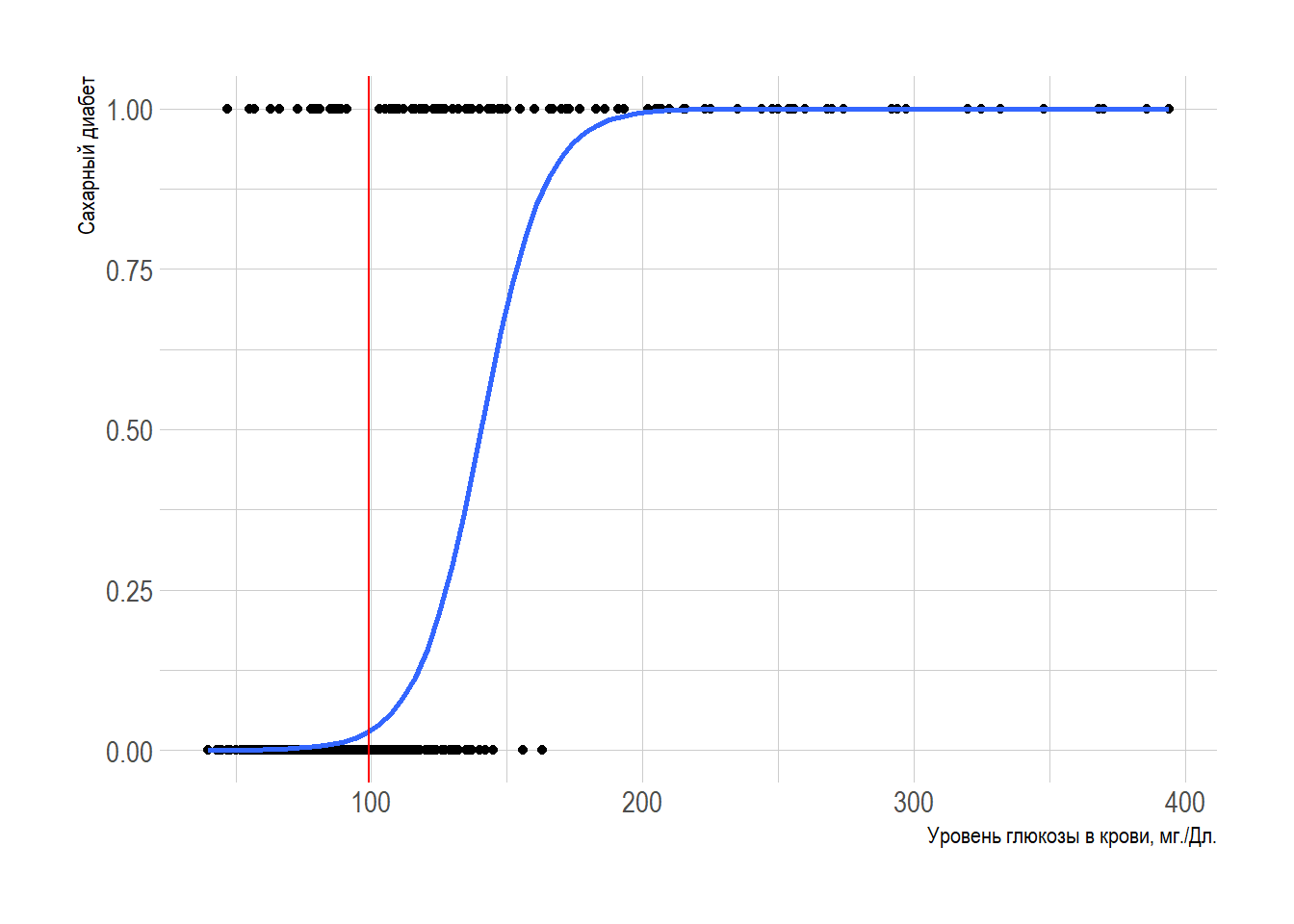
Оценим модель с помощью МНК.
mod_ols <- lm(diabetes ~ glucose, train)
stargazer(mod_ols, type = 'html', header = F)
| Dependent variable: | |
| diabetes | |
| glucose | 0.004*** |
| (0.0001) | |
| Constant | -0.320*** |
| (0.008) | |
| Observations | 3,121 |
| R2 | 0.390 |
| Adjusted R2 | 0.390 |
| Residual Std. Error | 0.130 (df = 3119) |
| F Statistic | 1,995.504*** (df = 1; 3119) |
| Note: | *p<0.1; **p<0.05; ***p<0.01 |
Но как её интерпретировать? Что значит отрицательный intercept? Если человек не сдавал анализ на глюкозу, его заболеваемость отрицательная? Также, вспомните Теорему Гауccа-Маркова, в которой сказано, что если выполнены несколько условий, одним из которых является линейность связи между зависимой и независимой переменной, то оценка МНК - лучшая несмещённая оценка. В нашем случае связь, очевидно, нелинейная, а оценки МНК - не лучшие. А значит нам нужен иной метод - Метод Максимального Правдоподобия.
Для оценки таких моделей у нас есть более удачная функция, чем обыкновенная прямая. Эта функция - сигмоид.
Логистическая функция
Напишем уравнение для линии.
y <- function(x){
intercept + b*x
}
Уравнение логистической функции.
S <- function(x){
1 / ( 1 + exp(-y(x)))
}
Параметры и интервал
intercept = 1
b = 1
x <- seq(-5, 5, by = 0.1)
Теперь нарисуем их:
tibble(x,
line = y(x),
sigmoid = S(x)) %>%
melt(id = 'x') %>%
ggplot(aes(x = x, y = value, color = variable)) +
geom_line(lwd = 1, alpha = 0.6) +
ylim(0, 1) +
theme_ipsum() +
labs(title = 'Сигмоид и линия', x = 'X', y = 'Диабет - 1, Здоров - 0')
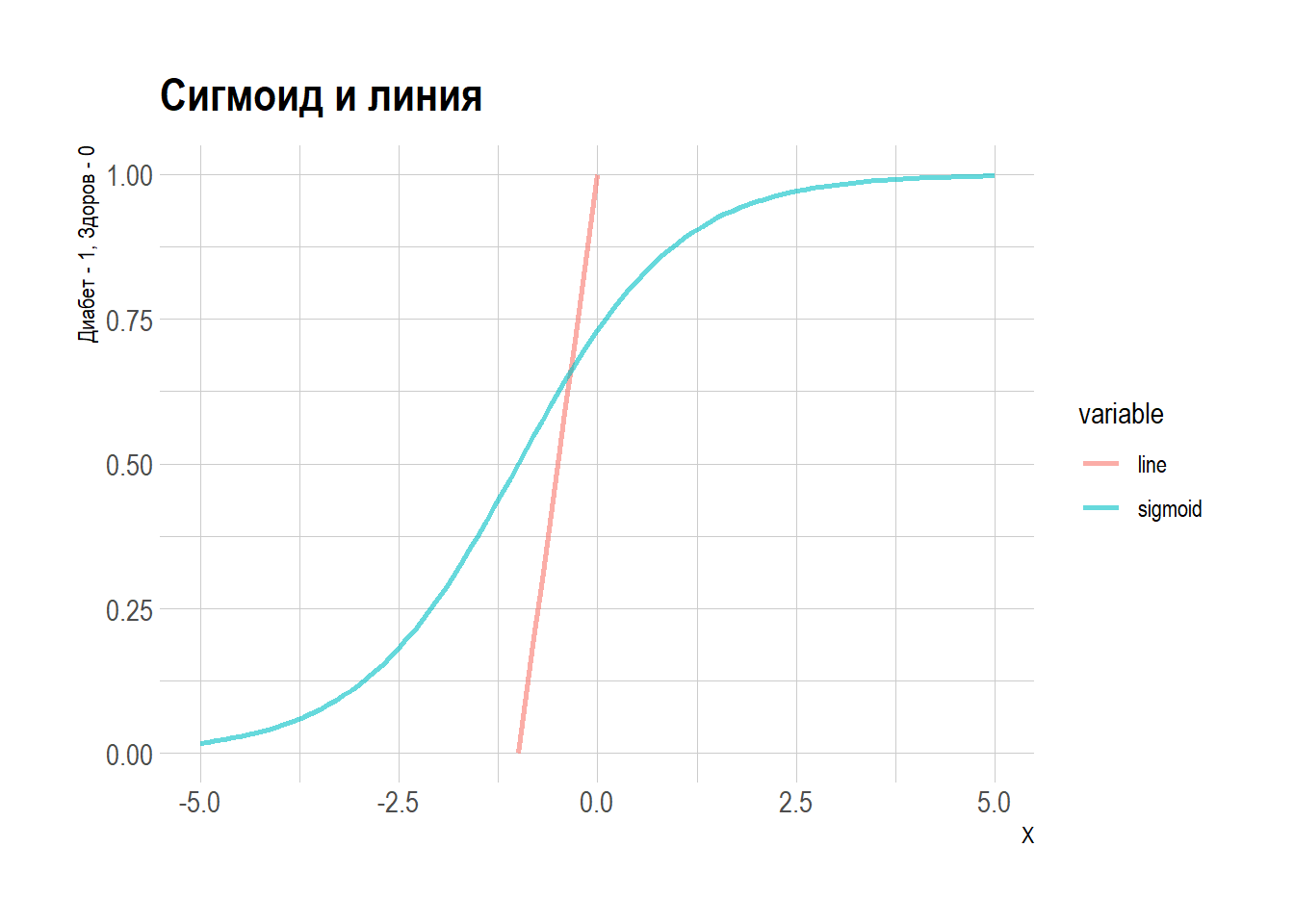
Чтобы получить больше интеиции о том, как устроена логистическая функция, Сравним две модели:
- МНК:
\(y_i = intercept + \beta_1 x_i + \epsilon_i\) - Логистическая регрессия:
\(y_i = \frac{1}{1 + e^{-(intercept + \beta_1 x_i)}} + \epsilon_i\)
Зафиксируем \(\beta_1\) и посмотрим, что произойдёт при изменении intercept.
Теперь зафиксируем intercept и посмотрим, что будет при изменении \(\beta_1\):
Оценим две модели:
mod_ml <- glm(diabetes ~ glucose, family = 'binomial', train) # МНК
mod_ols <- lm(diabetes ~ glucose, train) # ММП
stargazer(mod_ols, mod_ml, type = 'html', header = F) # сравним модели
| Dependent variable: | ||
| diabetes | ||
| OLS | logistic | |
| (1) | (2) | |
| glucose | 0.004*** | 0.079*** |
| (0.0001) | (0.006) | |
| Constant | -0.320*** | -11.347*** |
| (0.008) | (0.688) | |
| Observations | 3,121 | 3,121 |
| R2 | 0.390 | |
| Adjusted R2 | 0.390 | |
| Log Likelihood | -188.226 | |
| Akaike Inf. Crit. | 380.452 | |
| Residual Std. Error | 0.130 (df = 3119) | |
| F Statistic | 1,995.504*** (df = 1; 3119) | |
| Note: | *p<0.1; **p<0.05; ***p<0.01 | |
Ставим диагнозы при помощи модели
S <- function(x){
1 / (1 + exp(- (coefficients(mod_ml)[1] + coefficients(mod_ml)[2] * x)))
}
y <- function(x){
coefficients(mod_ols)[1] + coefficients(mod_ols)[2]*x
}
gl_test <- test$glucose # Столбец с значением анализа для тестовой выборки.
dia_test <- test$diabetes # Столбец с истинным значением диагноза.
# Создаём табличку
result <- tibble(gl_test,
dia_test,
pred_ols = y(gl_test),
pred_ml = S(gl_test)) %>%
mutate(pred_ml_01 = ifelse(pred_ml < 0.5, 0, 1)) # создайм ещё одну переменную со значением прогноза на основе предсказанной вероятности.
result %>%
head(10) # посмотрим на вервые 10 строк в таблице.
## # A tibble: 10 × 5
## gl_test dia_test pred_ols pred_ml pred_ml_01
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 77 0 0.00691 0.00527 0
## 2 NA 0 NA NA NA
## 3 102 0 0.113 0.0371 0
## 4 75 0 -0.00158 0.00450 0
## 5 87 0 0.0494 0.0116 0
## 6 84 0 0.0366 0.00915 0
## 7 84 0 0.0366 0.00915 0
## 8 83 0 0.0324 0.00846 0
## 9 84 0 0.0366 0.00915 0
## 10 83 0 0.0324 0.00846 0
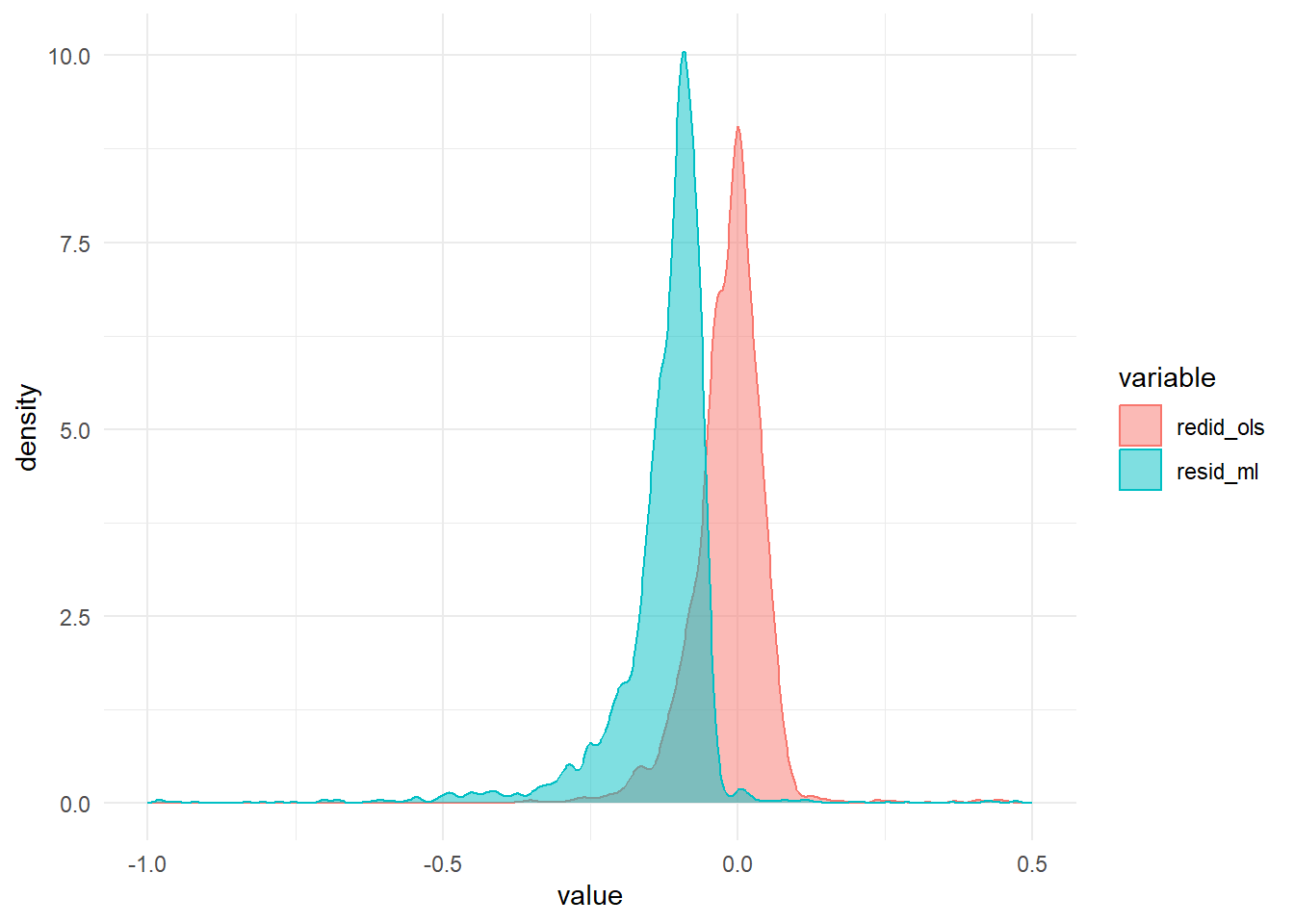
В отличие от оценок, сделанных при помощи МНК, оценки ММП смещённые. Это значит, что средняя ошибка в модели не равна 0.
residuals(mod_ols) %>% mean() # Ошибки в модели МНК.
## [1] 3.746551e-18
residuals(mod_ml) %>% mean() # Ошибки в модели ММП.
## [1] -0.09207685
Для большей наглядности, нарисуем распределение ошибок в моделях:
tibble(id = 1:length(residuals(mod_ols)),
redid_ols = residuals(mod_ols),
resid_ml = residuals(mod_ml)) %>%
melt(id = 'id') %>%
ggplot(aes(x = value, color = variable, fill = variable)) +
geom_density(alpha = 0.5) +
theme_minimal()+
xlim(-1, 0.5)
Добавим в модель больше параметров и сравним с первой:
mod_ml_1 <- glm(diabetes ~ glucose + age + education + cigsPerDay + totChol, family = 'binomial', train) # Диагноз теперь зависит от уровня глюкозы, возраста, уровня образования, интенсивности курения и уровня холестерина.
stargazer(mod_ml, mod_ml_1, type = 'html', header = F)
| Dependent variable: | ||
| diabetes | ||
| (1) | (2) | |
| glucose | 0.079*** | 0.077*** |
| (0.006) | (0.007) | |
| age | 0.057*** | |
| (0.021) | ||
| education | -0.233 | |
| (0.175) | ||
| cigsPerDay | -0.010 | |
| (0.016) | ||
| totChol | 0.003 | |
| (0.003) | ||
| Constant | -11.347*** | -14.425*** |
| (0.688) | (1.557) | |
| Observations | 3,121 | 3,013 |
| Log Likelihood | -188.226 | -173.875 |
| Akaike Inf. Crit. | 380.452 | 359.750 |
| Note: | *p<0.1; **p<0.05; ***p<0.01 | |
Сравним, какая модель стваит диагнозы: с однйо объясняющей переменной или с несколькими:
S <- function(x){
1 / (1 + exp(-x))
}
predict_ml <- predict(mod_ml, test %>% select(-diabetes)) %>%
S()
predict_ml_1 <- predict(mod_ml_1, test %>% select(-diabetes)) %>%
S()
predictions <- tibble(true_diagnoses = test$diabetes,
prob_ml = predict_ml,
prob_ml_1 = predict_ml_1) %>%
mutate(dia_ml = ifelse(prob_ml < 0.5, 0, 1),
dia_ml_1 = ifelse(prob_ml_1 < 0.5, 0, 1)
) %>%
mutate(error_ml = ifelse(dia_ml == true_diagnoses, 0, 1),
error_ml_1 = ifelse(dia_ml == true_diagnoses, 0, 1)
)
predictions %>%
tail(10) # последние 10 наблюдений в табличке
## # A tibble: 10 × 7
## true_diagnoses prob_ml prob_ml_1 dia_ml dia_ml_1 error_ml error_ml_1
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 0 0.00174 0.00231 0 0 0 0
## 2 0 NA NA NA NA NA NA
## 3 1 0.720 0.815 1 1 0 0
## 4 0 0.00668 0.0195 0 0 0 0
## 5 1 1.00 1.00 1 1 0 0
## 6 0 0.0200 0.0572 0 0 0 0
## 7 0 0.00915 0.00807 0 0 0 0
## 8 0 0.0252 0.0472 0 0 0 0
## 9 0 0.00571 0.00244 0 0 0 0
## 10 0 0.00571 0.00635 0 0 0 0
predictions$error_ml %>% na.omit() %>% sum
## [1] 9
predictions$error_ml_1 %>% na.omit() %>% sum
## [1] 9
Удивительно, но обе модели ошиблись в диагнозах менее 20 раз из 800 - менее 5%! Модель с одной объясняющей переменной показала отличную способность прогнозировать диагнозы, потому что мы выбрали наиболее значимую объясняющую переменную - уровень инсулина.